
在美团一些大型业务开发中,经常会出现大家觉得系统维护不下去了,一个反复被提及的词就是代码复杂度高。但是后台业务确很少有类似的声音,其实后台业务的复杂度也不低,但是为什么会有类似的情况发生呢,其实我认为对是否可维护不完全是客观的,比如考虑以下几个 case
- 有人接手前人的项目后,会觉得可维护性差,然后进行重构工作,但是在上一任维护人上并没有类似的想法
- 很多人会说 react 项目太复杂,不好开发维护,但是 react core team 的人没觉得不好维护
- 架构师走了之后,团队成员换了一批会觉得之前的东西很难维护
- 业务支持多个业态,或者业务干脆换了一个方向,各种原因下系统还是局部复用的,整个系统会让人感觉不可维护
可维护性和什么有关
我将上面提到的情况大致的划分成了下面的表格的四个维度(链接为我对应的具体的思考):
| 客观情况 | 人相关 |
|---|---|
| 业务复杂度:《🐣系统中复杂度体现在哪些方面》《🐣为什么复杂的业务不好做》 | 技能:拥有一定深度和广度 《✅如何看待技术深度与广度》 |
| 代码与架构:《🐣如何做好前端架构》 | 熟悉程度:(时间 +意愿)*理解力/频次 |
在这四个维度中,业务复杂度是无法改变的,对项目熟悉程度也需要精力(时间+意愿),所以回到优选项目我们说它难以维护的原因可以如下分析:
- 熟悉程度低:为了赶排期,经常协调人协助开发一些本来不是他负责的业务功能,导致大家对项目平均熟悉度都偏低
- 架构不合理:过去每周2大迭代+3迭代,同时排查很多线上问题导致大家没精力进行周全的技术设计
- 业务复杂度:团长,用户,新人,老客,促销,活动等等聚集到一起业务case相对复杂
- 技能:低职级的同学主力开发,KP精力更多在排查线上问题,高职级的事务性工作多,导致项目技能平均投入偏低
整体形成了如下图红色部分的负向循环:
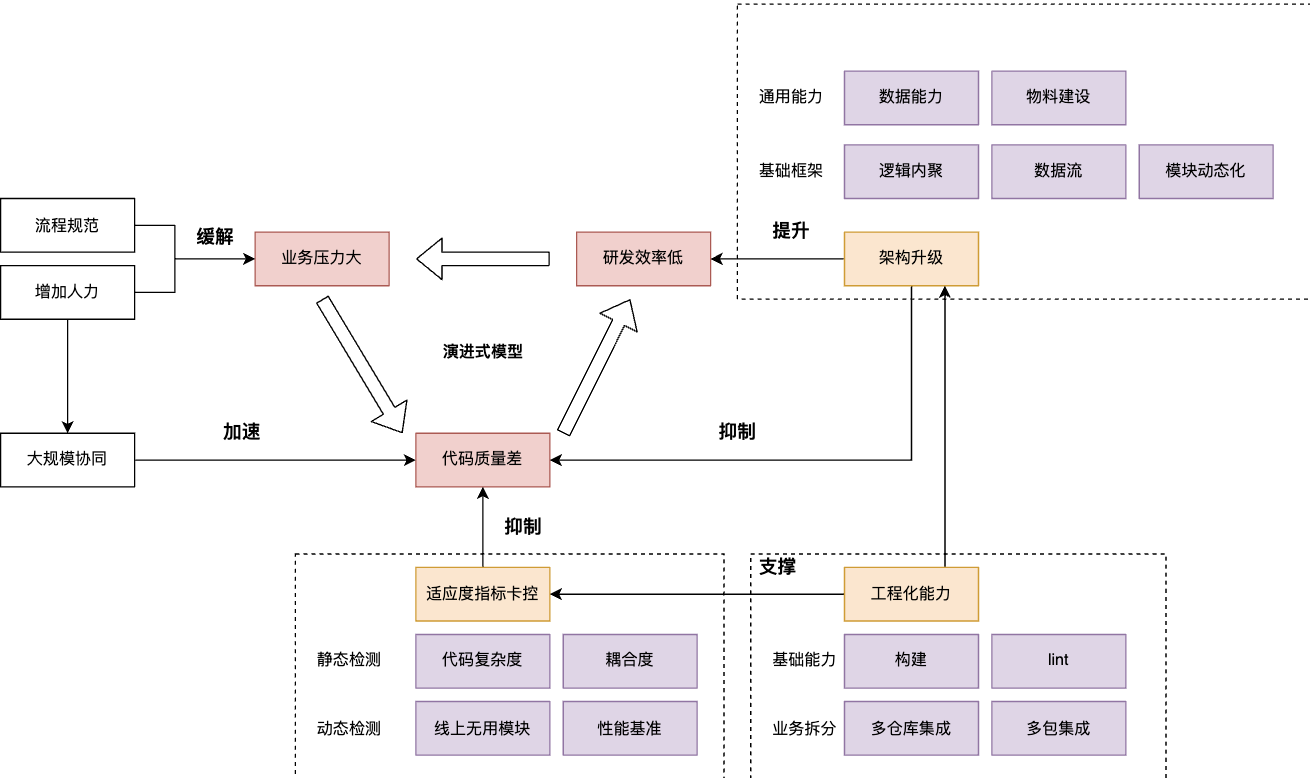
如何提高可维护性
(1) 业务复杂度
业务变复杂是技术没办法解决的,是客观的商业行为导致的。业务本身越复杂,所包含的信息量就会越大,复杂度就会很高,而系统架构设计是无法消除业务整体复杂度的,它只能让复杂度可以被拆分,让团队不同的人可以面对一个被切分后的相对可控的业务难度,但架构师(系统主R)还需要将所有被切分的信息聚合起来,这些工程方法客观上降低了人类理解复杂度,但实际增加了系统实体复杂度。不过降低理解复杂度可以客观提高系统可维护性,所以我们还是要对业务有一个很好的认识从而进行对应的代码与架构的设计。
(2) 代码与架构
2.1. 如何做好架构
首先要明确的一点是不要在开发过程中教条的应用一些设计模式和架构模型,所有的架构都是为了合理的将业务抽象成对应的技术实现,抽象好的表现是适应度函数的曲线比较贴合业务真实复杂度,抽象的不好,一个简单的页面也会让人难以理解。《🐣如何做好前端架构》
架构另一个作用主要在业务拆分,我们需要通过确定模块开发所需了解的最小知识给实际业务开发同学做减法,不需要理解的模块就不要轻易展示出来,最大程度减少开发者的心智负担。
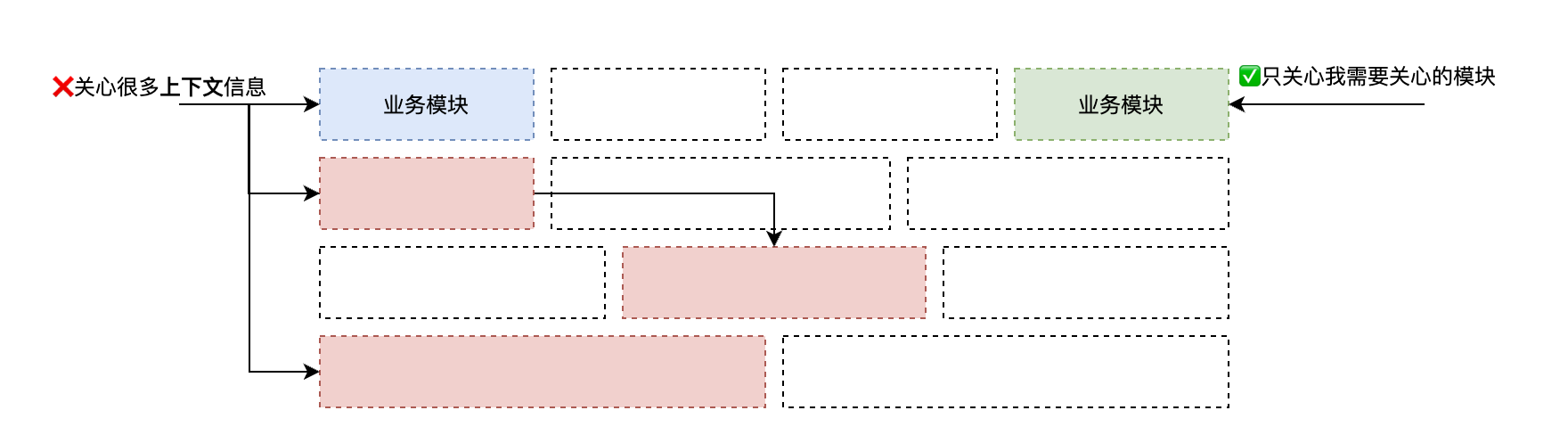
前端项目中一般分层做的相对较好,比如常规做法我们会把一个业务中的前端项目分为 容器层,基础能力层(网络,日志,安全),物料层,业务能力层(登录,支付,购物车)等等,但是具体到每个业务模块对业务的抽象可能做的还不够,目前集中讨论的都是数据流和框架(React/Vue),但是这些只是手段,并不能帮我们很好的抽象业务逻辑。服务端在这些事情上有很多的抽象比如六边形架构,DDD 等等,前端需要在这件事情上有更深入的探索。
另外一个合理的架构还需要包含文档,测试等帮助人理解业务&代码的配套设施。
2.2.如何衡量代码是否可维护
因为前端再过去的复杂度一直不是很高,通过框架可以很好的解决维护的问题,所以前端在这件事情上面关注的还是比较少。直到最近几年出现很多巨石应用,才在一些业务团队中被反复提及,但是目前主要衡量的可维护的方法是通过质量指标和主观感受来进行衡量,这很显然没太多的说服力。我们实际期望的获得一个适应度函数(Fitness Function)Fi,公式为:Maintainable = Fi(Feature) ,其中业务功能变化的时候我们得到的可维护性也尽可能的贴合,这里尽可能的贴合是指我在《🐣系统中复杂度体现在哪些方面》中提到三点:
- 不要修改放大 (Change Amplification)
- 减轻认知负担 (Cognitive Load)
- 减少未知的未知 (Unknown Unknown)
如何衡量是否贴合比较难的地方在于Feature的变化是多种多样的,业务的逻辑就是没有逻辑,我们没办法正面求得Fi,只能通过一些侧面的指标来衡量。业界上有很多理论(见备注),从两个方面的指标来说明:
源码方面
指标:LLOC 相比于传统的 LOC,明显LLOC更稳定
// LOC 1
// LLOC2
if(true) console.log('hello');
// LOC 3或4
// LLOC 2
if(true) {
console.log('hello');
}指标:Halstead Complexity(HV) GitHub - aametwally/Halstead-Complexity-Measures: Calculate Halstead complexity software measures using ASTParser. These metrics are computed statically, without program execution.
指标:Cognitive Complexity (CC)
认知复杂度 下面的两种方法有着相同的圈复杂度,但是在可理解性方面有着显著的不同
 圈复杂度的数学模型赋予了这两种方法同等的权重,但是直观上很明显 sumOfPrimes 的控制流比 getWords 更难理解。这就是为什么认知复杂性放弃了使用数学模型来评估控制流,转而使用一套简单的规则来将程序员的直觉转化为数字。
我们代码中的一个 bad case 用认知复杂度可以很好地衡量出来如下:
圈复杂度的数学模型赋予了这两种方法同等的权重,但是直观上很明显 sumOfPrimes 的控制流比 getWords 更难理解。这就是为什么认知复杂性放弃了使用数学模型来评估控制流,转而使用一套简单的规则来将程序员的直觉转化为数字。
我们代码中的一个 bad case 用认知复杂度可以很好地衡量出来如下:
a && b //圈复杂度:2 ,认知复杂度:2
a && b && c && d // 圈复杂度:4 ,认知复杂度:2
a || b && c || d // 圈复杂度:4 ,认知复杂度:4架构方面
内聚性 共生性(耦合) 后续会写一篇文章单独展开讲
指标函数
Maintainability Index:由 Paul Oman and Jack Hagemeister 在1992年提出,它是若干种度量的混合,包括 HV, CC 以及 LLOC 三个不同指标,原始公式为:MI=171−5.2lnV−0.23G−16.2lnL SEI 的衍生版本 MI=171−5.2log2 V−0.23G−16.2log2 L+50sin(2.4C)
还有 Visual Studio 衍生版本, Radon 衍生版本等等
通过以上的任意一个函数都可以近似求得适应度指标,我们就可以观测业务代码在迭代过程中的指标变化,从而得到是向好还是向坏的一些衡量标准,达到卡控代码的目标
(3) 熟悉程度
这块主要通过流程规范来解决,比如锁定主R,减低迭代频次,提高系统设计细节要求等方法提高团队对代码的平均熟悉水平
(4) 技能
这块主要就是看岗位胜任度了,选用育励汰等方法论
